Running your models in production
In this tutorial, you will learn how to run the models you trained using Arkindex.
This section is to be followed and carried out after annotating the Pellet dataset and training:
As a result, you will produce segmented text_line elements using YOLO, which will then be transcribed using PyLaia, on all the pages you wish to process.
Optional step - Import more images to process¶
If you wish to also try out your newly trained models on your own images, you can import some by following this section or even upload a large image set by following this one.
Start your process¶
Create the process¶
Once all the images you want to process are available in your Arkindex project, you can create a process.
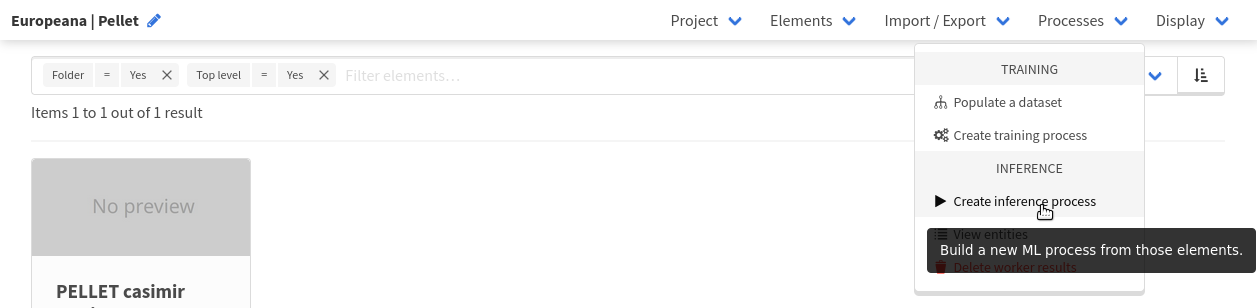
Browse to the page of the Europeana | Pellet project and click Create inference process in the Process dropdown menu.
Select elements¶
You will be redirected to a new page allowing you to filter the elements to process.
The segmentation model you trained will work on page elements and detect text_line and illustration children. The transcription one will search for any text_line element appearing on the pages and create transcriptions.
Therefore, from this page, you can activate the Load children toggle and filter the elements by Page type:
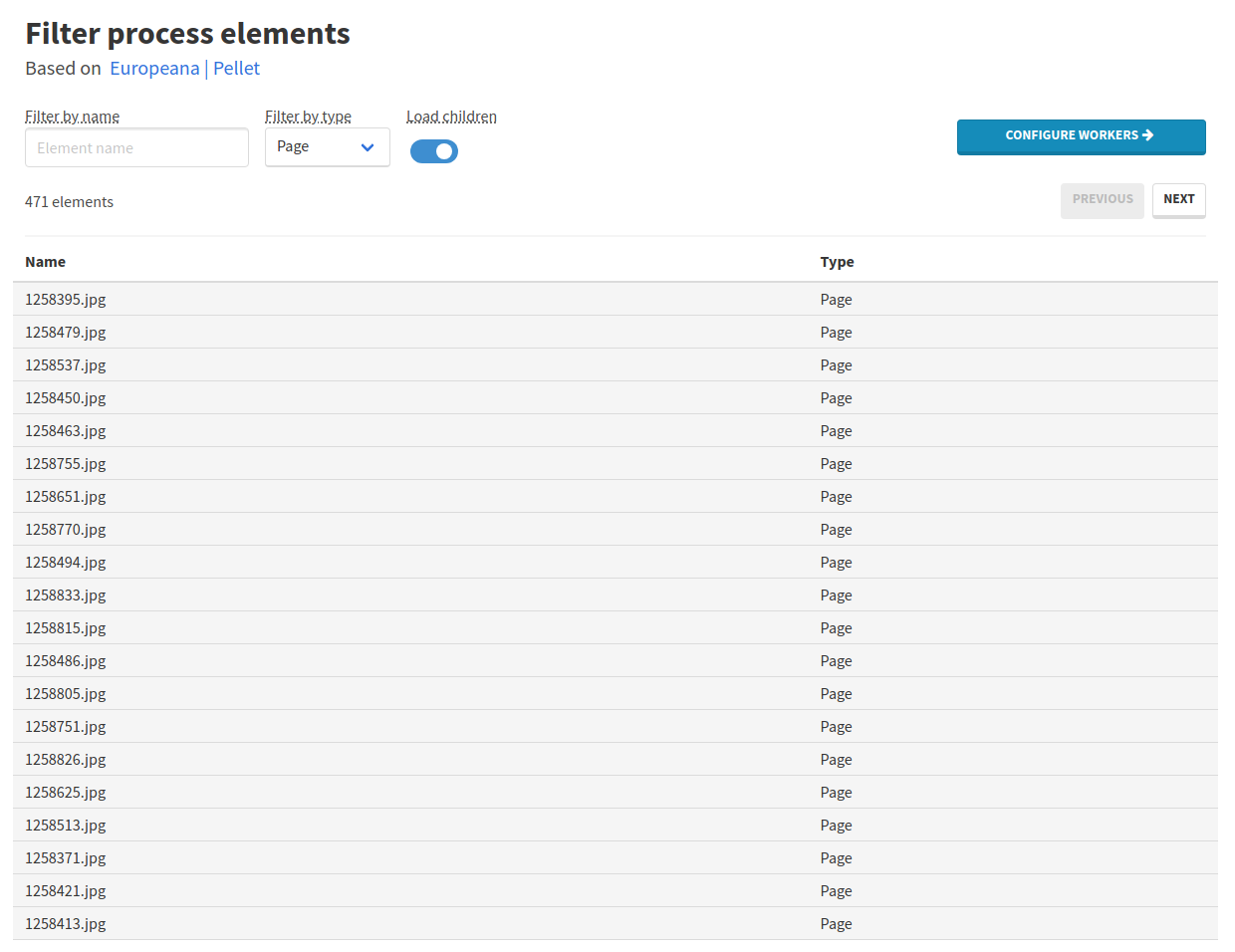
Once your elements are properly filtered (when processing only the Pellet dataset, 471 pages should be listed), you can proceed to workers configuration by clicking the Configure workers blue button.
Add YOLO and PyLaia workers¶
Press the Select workers button, filter by the Image-segmenter worker type, search for YOLO Inference and press the Enter keyboard key.
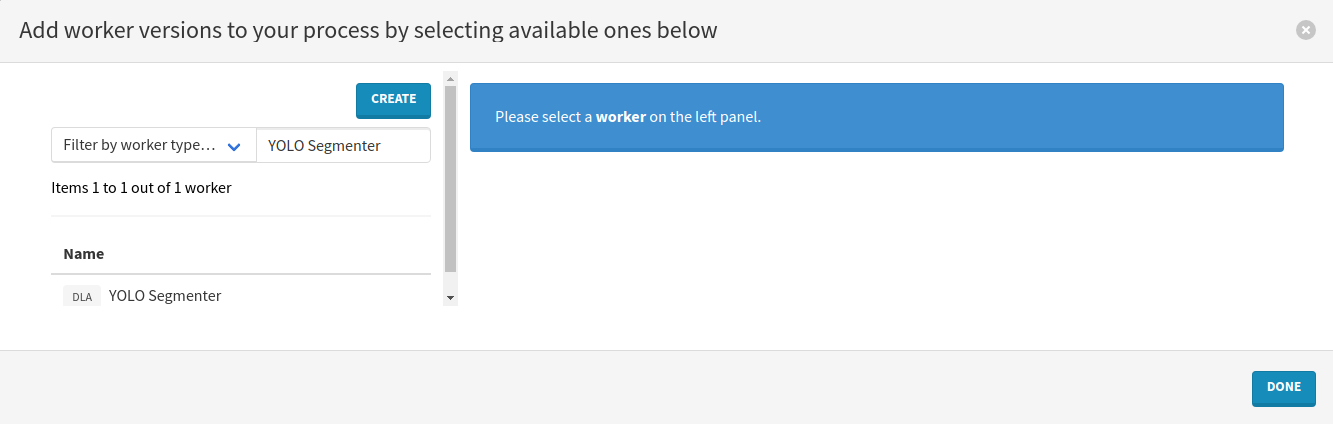
Click on the name of the worker on the left and select the recommended version by clicking on the Add to process button in the top-right corner.
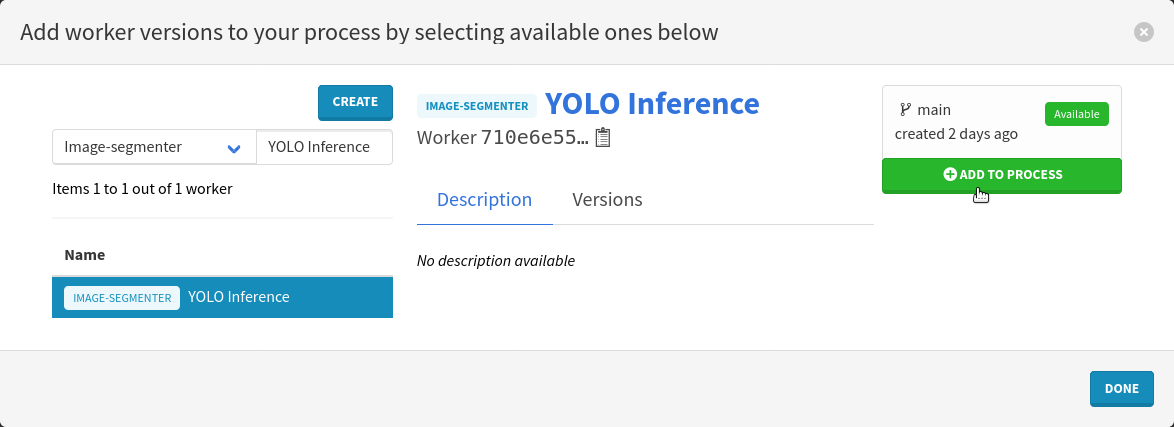
We need to repeat the same steps for the PyLaia worker. Reset the worker type filter and the search field, input PyLaia Inference instead and press the Enter keyboard key.
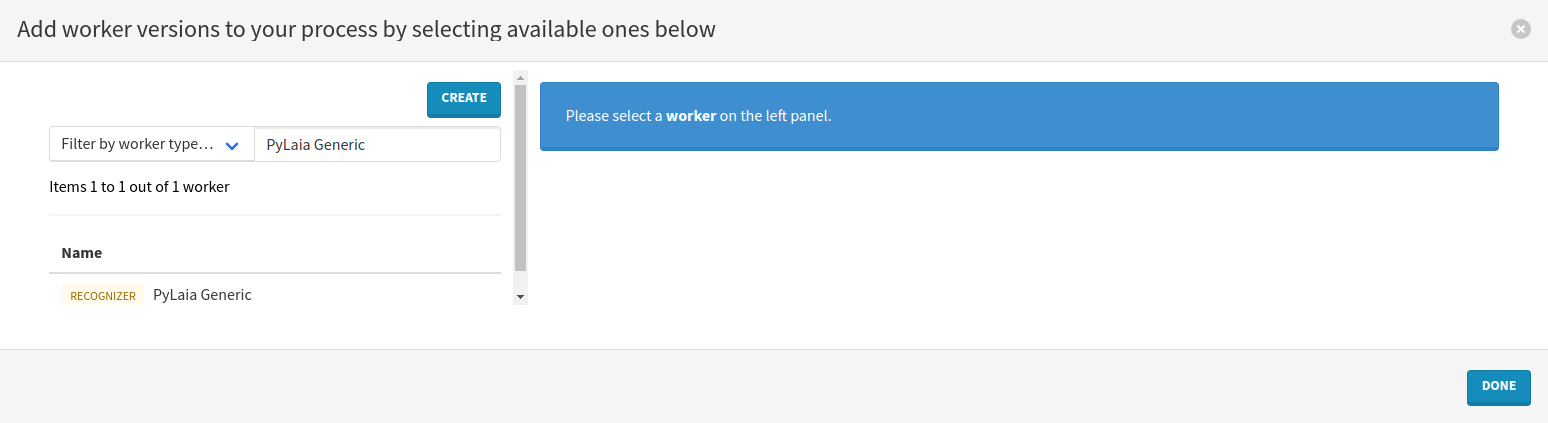
Click on the name of the worker on the left and select the recommended version by clicking on the Add to process button in the top-right corner.
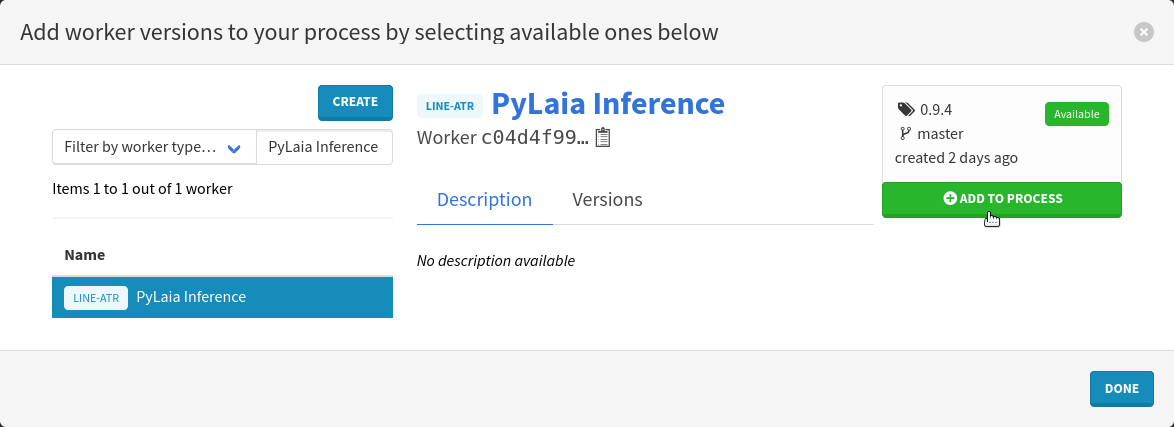
Close the modal by clicking on the Done button on the bottom right.
Use your own models¶
Now it is time to select the models you trained.
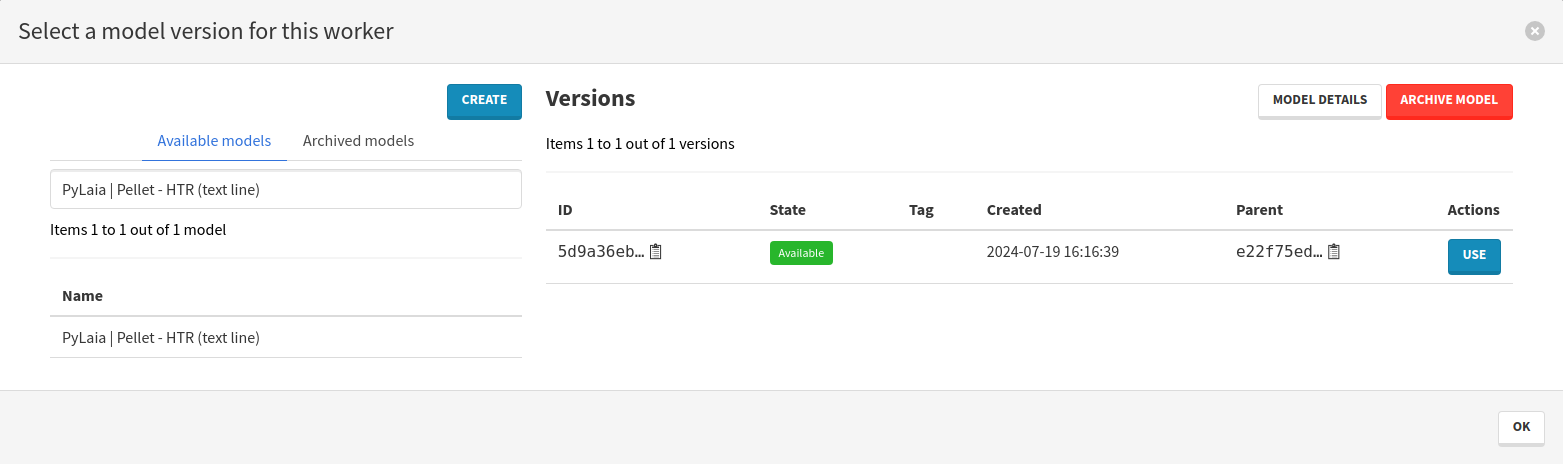
Click on the button in the Model version column of the YOLO Inference worker. In the modal that opens:
- Look for the name of your trained segmentation model,
- Add the model version by clicking on Use in the Actions column,
- Close the modal by clicking on Ok, in the bottom right corner.
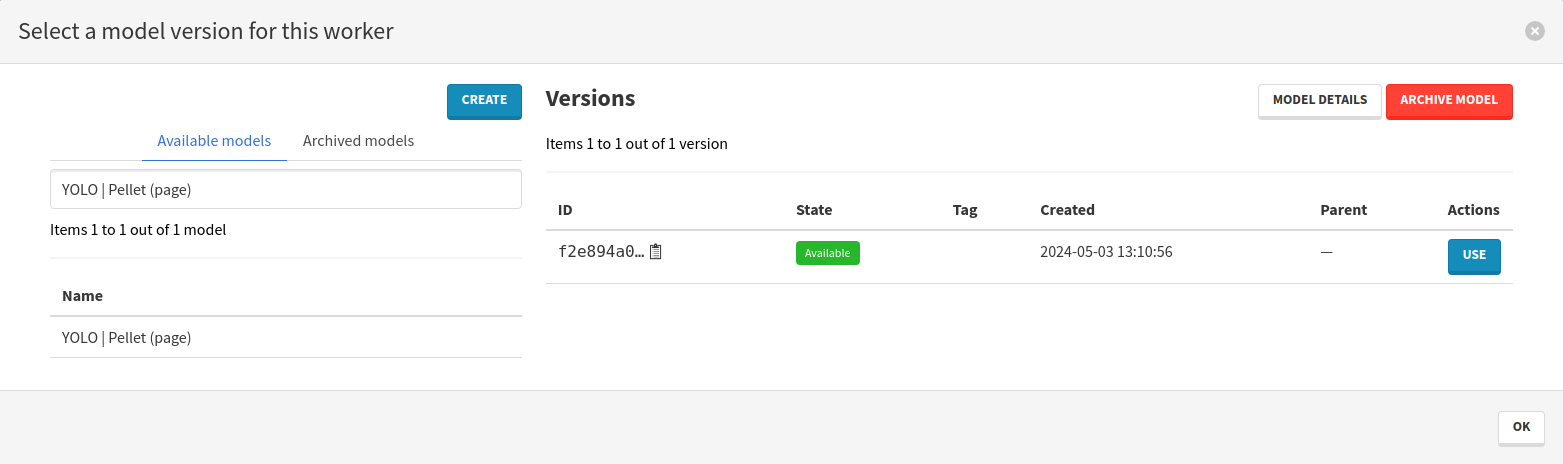
Repeat the exact same steps but for the PyLaia Inference worker, searching for the transcription model you trained this time.
Configure the workers¶
Workers can be configured to parametrize their execution, in our case, the YOLO Inference already perfectly suits our needs with its default configuration. We will not have to configure it. On the contrary, the PyLaia Inference worker requires a few adjustments.
Prior, we need to find the YOLO Inference version UUID. To do so:
- Click on the
YOLO Inferencename, this will open a new tab,
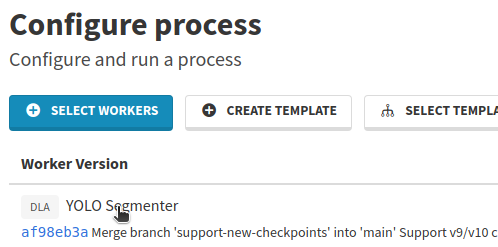
- From there, copy the UUID displayed next to Version just below the worker name,
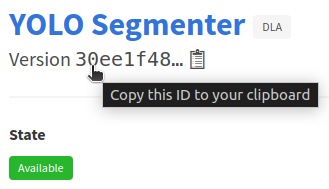
- Save the copied UUID, we will use it in a few moments,
- Close the tab that was just opened, you are back to the Process configuration page.
Configure the PyLaia Inference worker by clicking on the button in the Configuration column, this will open a new modal.
Select New configuration on the left column, to create a new configuration. Name it after the dataset you are using.
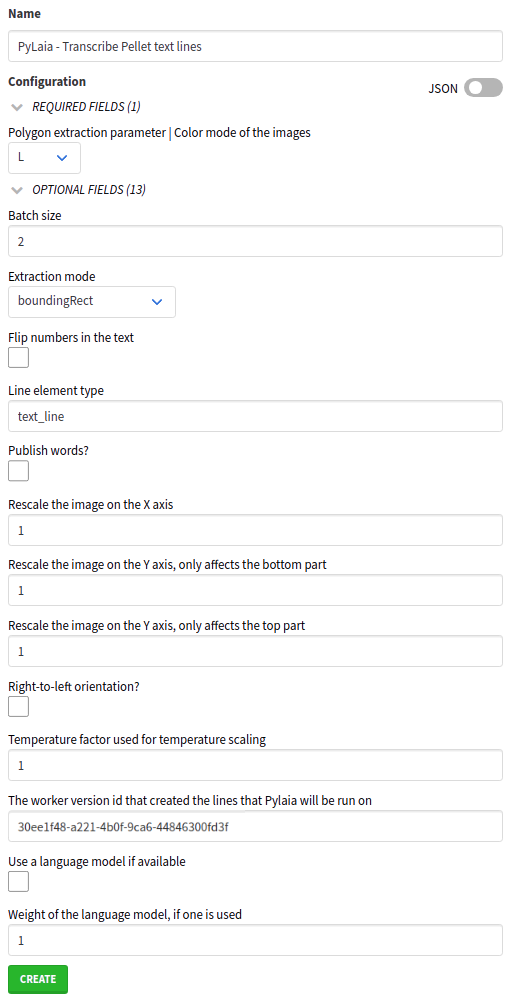
The most important parameters are:
- Batch size (optional): a higher value will make the inference faster but will also increase the memory usage,
- Line element type: the default value is
text_linewhich is already the slug of the element type we want to transcribe, - The worker version id that created the lines that Pylaia will be run on: this is where you have to paste the UUID you copied from the
YOLO Inferenceversion. It will prevent PyLaia from seeing lines other than those segmented by YOLO.
Click on Create then Select when you are done filling the fields.
Set the dependencies¶
As explained just above, we want the PyLaia Inference worker to process the text_line elements produced by the YOLO Inference worker. It means that the YOLO worker is a dependency of the PyLaia one. The segmentation step must run before the transcription.
To follow this requirement, click on the button in the Dependencies column of the PyLaia Inference worker. In the modal that opens:
- Add the
YOLO Inferenceworker by clicking on the green + button, - Close the modal by clicking on Ok, in the bottom right corner.
Run your process¶
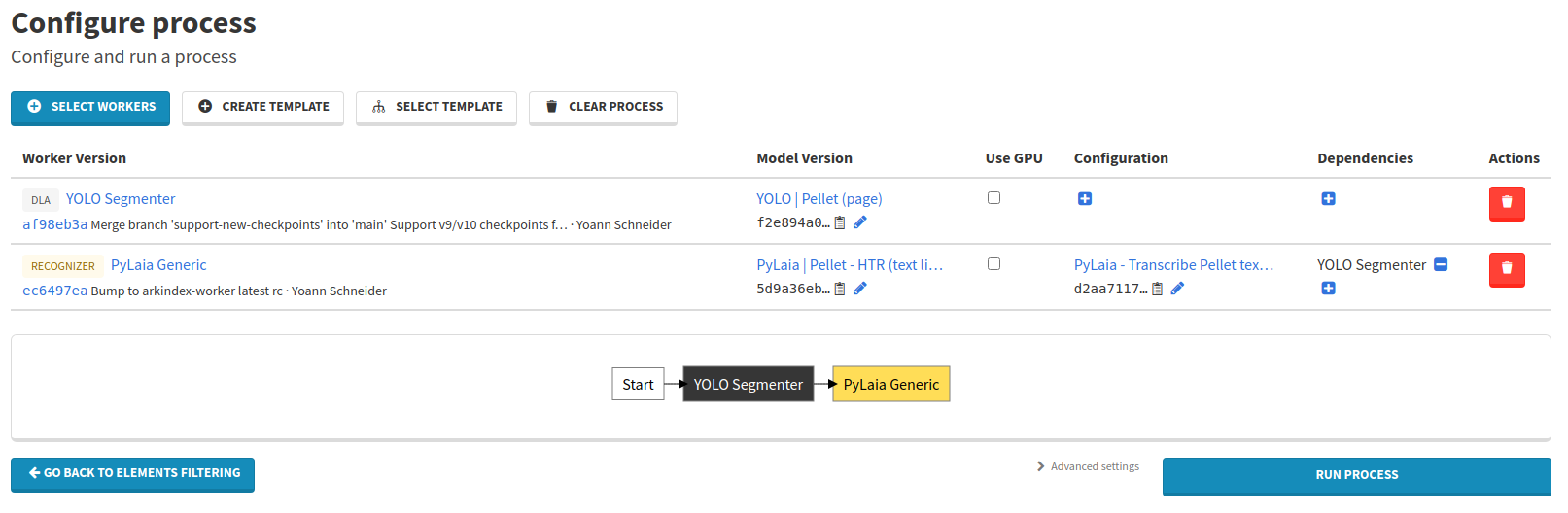
Your process is now fully configured and ready to run! You can launch it using the Run process button.
While it is running, the logs of the tasks are displayed. Multiple things happen during this process:
- Elements to process are listed by the
initialisationtask. - The
yolo-segmenter_xxxxxxtask: - browses provided elements, - segments them using your trained model, - producestext_lineelements, published back to Arkindex. - The
pylaia_generic_xxxxxxtask: - lists alltext_linesfrom the provided elements that were segmented by the previous task, - predicts a transcription on them using your trained model, - publishes transcriptions directly on thetext_lineelements.
Wait for the process completion before moving to the next step.
Check the results¶
To see the predictions of your two models, browse back to the PELLET casimir marius folder in your project. There you can click on one of the displayed pages and you will be able to tell how well your YOLO model segmented the image.
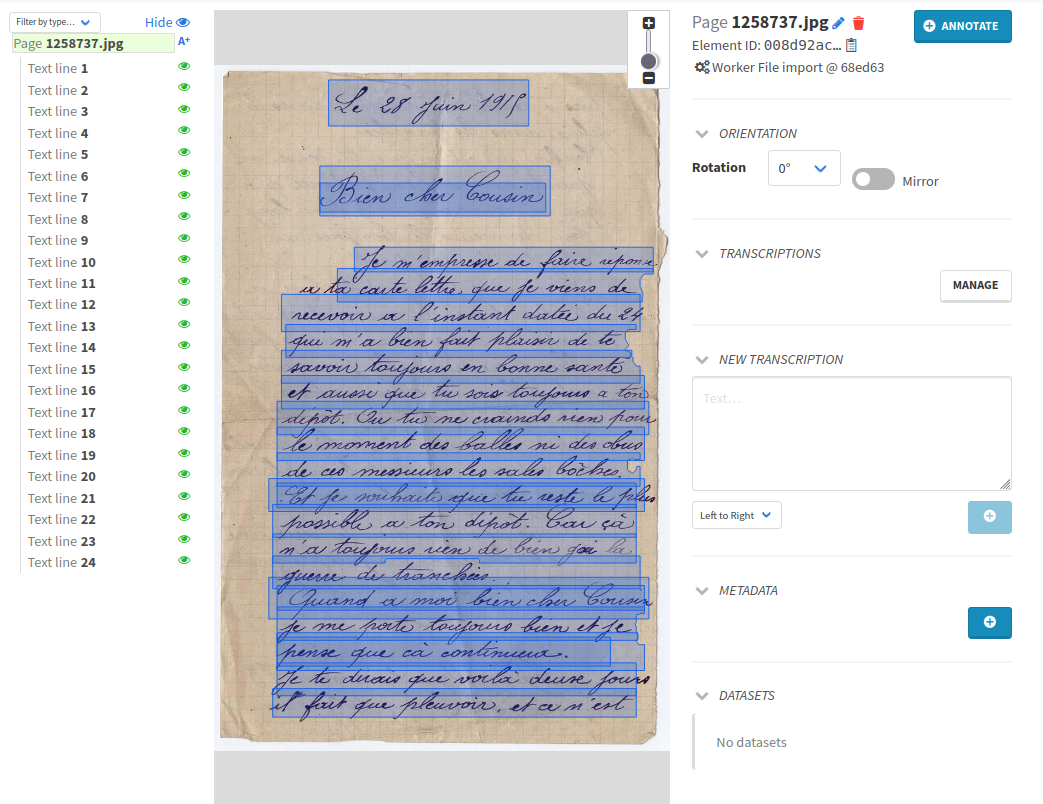
To visualize PyLaia predictions, you can highlight a text line by selecting it from the children tree displayed on the left.
Once the text line is highlighted, its transcriptions are displayed on the right, in a dedicated section.
If your text line has multiple transcriptions:
- Callico is mentioned on the transcriptions annotated by humans,
- PyLaia is mentioned on the predicted transcriptions.
As you might see, your models are working but not perfectly. Segmented elements are sometimes a bit off or zones may have simply been missed by YOLO. Transcriptions from PyLaia can approach perfection or be really off the mark. A dedicated section explains why and how to train better models using Arkindex and Teklia’s software.
Next step¶
Now that you have produced segmentation and transcription results in Arkindex, you may want to extract them from the platform to use elsewhere. We will explain how to export your data to PAGE XML format in the next page.