Arkindex aims to provide Machine Learning tools to process your documents.
Document processing is done using successive specialized actions ensured by workers. A worker does one action on one element at a time, and report its results to Arkindex.
Any processing action allowed by the API can be implemented as a worker. This includes:
Depending on your needs, the computational work can be distributed among multiple servers to handle up to millions of documents.
Some workers implemented by Teklia have been made available on demo.arkindex.org to any registered users, so you can try them on your own documents.
You must have an admin access to a project in order to create a process from its elements. You can run a process on the projects you own, or have been granted an admin access.
You can either use the selection tool to manually choose elements or start a process from a folder (e.g. to process all pages inside a book).
You can manually select elements while navigating on Arkindex.
To add an element to the selection, you can either:
Selections are made by project. You can see all the elements you selected by clicking on the document icon right before the user menu.
Once you are on the selection page, you can create a process on a project selection from the Actions dropdown.
You may create a process directly from the navigation. In this case, the filters you are using will be transferred to the process creation page. Filters include elements name and type.
For example, you can create a process from all the text lines recursively listed inside a folder.
Once your filters are set, you can create a process from the Actions menu in the element header.
Directly after creating a process, you will be redirected to a page that lists concerned elements. From this page, you can check the element count or adjust the filters.
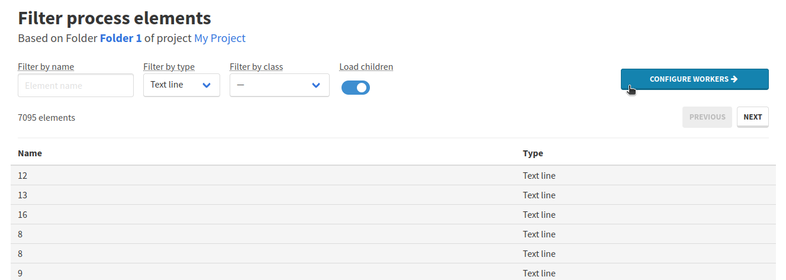
Once the elements list looks fine, you can click on Configure workers to create a Machine Learning workflow for this process. You can still go back to the filtering page until you finish the configuration and start the process.
The second page of process configuration allows you to define a combination of workers, in order to match the needs of your Machine Learning workflow.
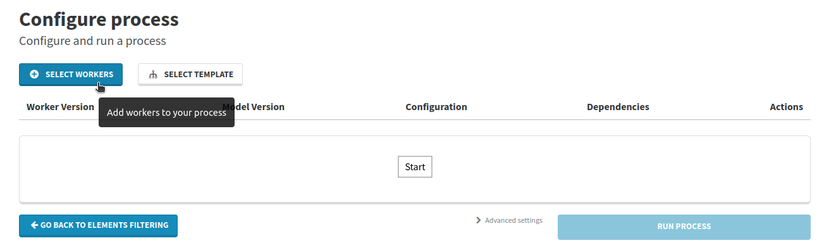
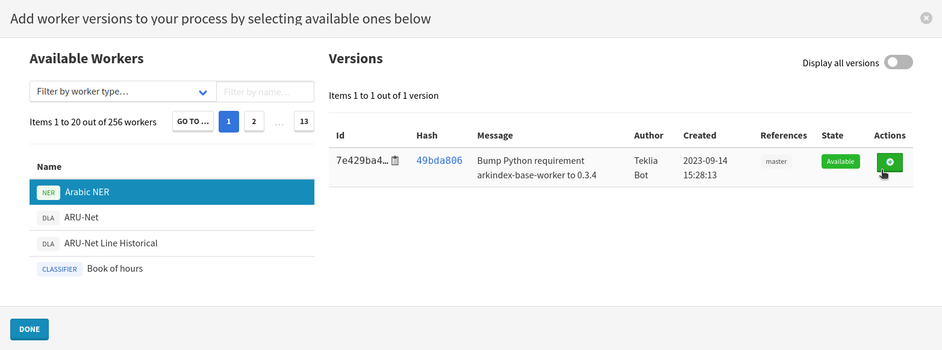
A modal will allow you to select a worker in order to add one of its versions to your process.
Most of the time you should use the version with the master tag, as it is the latest stable version.
Once you have selected all the workers you need, you can close the modal. A diagram explaining the execution order will then appear in the main display.
If a worker requires results produced by another worker, you can add dependencies. As you add dependencies, the diagram representing the workflow gets updated to reflect the execution order.
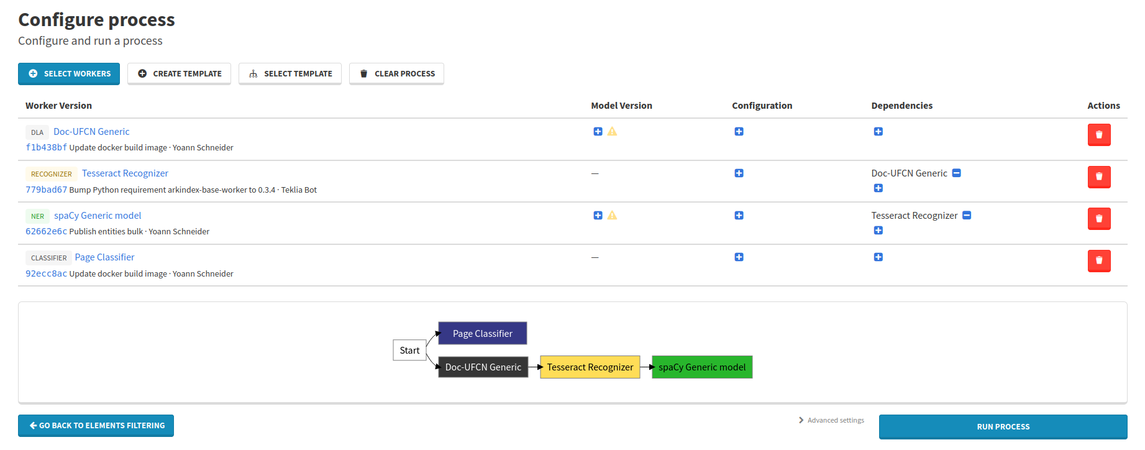
In the example above, Tesseract Recognizer creates transcriptions on text lines. Doc-UFCN Generic creates these text lines, so it needs to run first. Therefore, Tesseract Recognizer depends on Doc-UFCN Generic. Similarly, spaCy Generic model requires transcriptions to recognize entities in, and so spaCy Generic model depends on Tesseract Recognizer.
The Page Classifier on the other hand doesn't require results from any other workers, and has no dependencies.
You can also select a model for workers that require one, as well as a worker configuration.
Once your process is correctly configured, you can click on the Run process, button to execute your process. You will be redirected to the process status page.
Once a process is started, it cannot be modified. In case something is wrong, you may stop it and create a new one.
From the status page you can see the evolution of your process. Each successive worker will produce logs depending on its execution. When a task is completed with no error, it will be displayed in green.
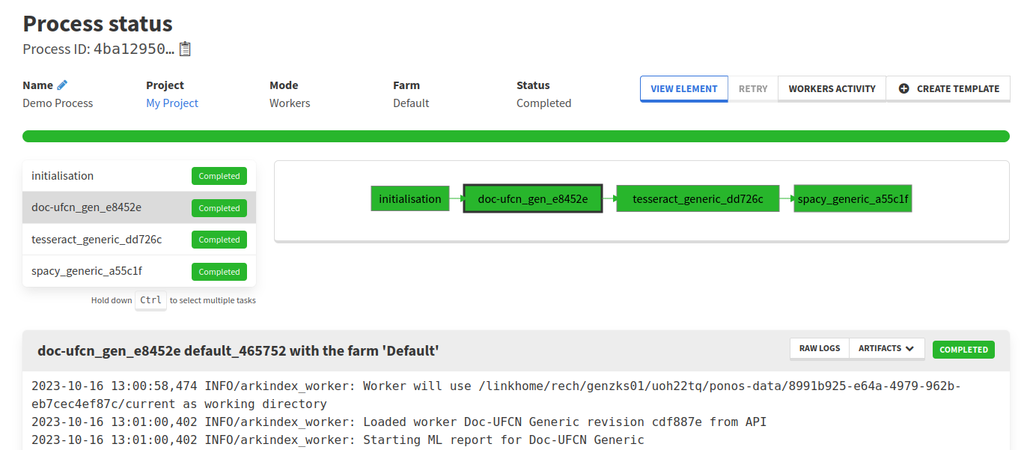
Once the complete workflow is finished, you can access your processed elements directly from the View element button.
The advanced settings section contains advanced parameters for running the workflow:
Split the process in different chunks and run them in parallel. Depending on the configuration of the Arkindex instance, this option is activated or not.
Run the workflow on a specific group of computing resources.
Use the tracking of elements processing. This option is enabled by default.
The tracking allows to see the completion of a process in real time for each worker. A link to the activity is available on the process status page.
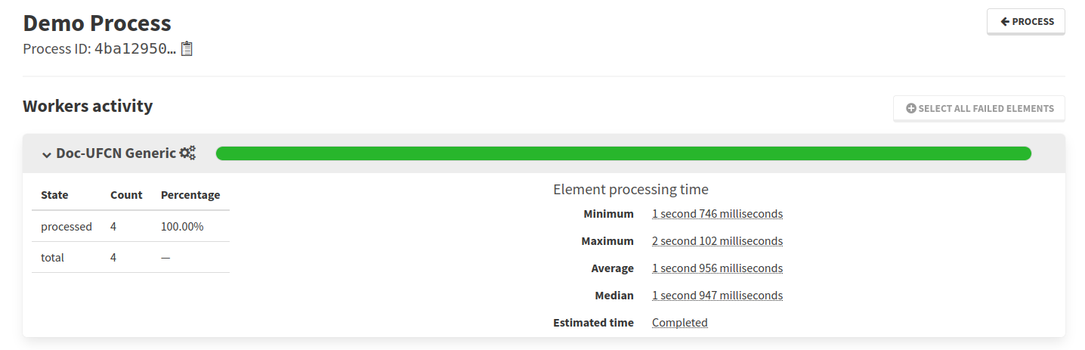
Each element will be updated to a specific state while being processed.
| State | Description |
|---|---|
| queued | Element's processing has not started |
| started | Element is being processed and has been locked by the worker |
| processed | Element has been successfully processed |
| error | The worker encountered an error while processing this element |
Workers activities enable a better recovery when errors occurred during a process. When clicking on the Retry button or creating a new process with the same worker, already processed elements will be skipped because ML results generation are idempotent.
If some elements are locked in a started state and could never complete, you will have to wait a 1 hour timeout to start processing them again with this worker.
Reduce processing time using local caching. This option is in Beta mode and may cause problems on some workers.
Reduce processing time by using a GPU. Not all workers support GPU usage, and some will require it.
